Por exemplo, imagine produzir um relatório com uma query envolvendo três tabelas, na ordem de milhões de linhas cada, e dispondo-se de um tempo curto e crítico. Isso pode ser conseguido se transferirmos conscientemente algum trabalho de organização e seleção de dados, para a memória.
A opção pelo tratamento consciente de dados em memória, além de aliviar o trabalho do servidor, poderá dar um aumento significativo de velocidade ao processamento.
Ou seja, são várias as situações que admitem esse tipo de solução, pois nem sempre é conveniente ou viável que se reestruture o banco de dados para atender a uma situação específica. Além disso, existem situações em que é necessária a manipulação de massas de dados que não estão sob controle de um SGBD.
O Delphi disponibiliza um poderoso dispositivo que nos auxilia no tratamento de dados, que são as listas em memória, da classe TSTRINGLIST, as quais permitem criar e manipular listas, de modo simples e eficiente.
Um objeto STRINGLIST dispõe de dois métodos que simplificam o seu uso, Sort e Find, que, combinados, fazem grande parte do trabalho.
Este artigo trata do uso prático desse recurso, e para tanto desenvolveremos 3 casos, de complexidade crescente, dando oportunidade a que sejam apresentadas algumas técnicas interessantes. Os casos são estudados a seguir.
Caso 1. Verificando se existe.
Este primeiro caso é bem simples, meramente ilustrativo dos métodos da classe.
Suponhamos uma tabela, tab_A, que desejamos filtrar, e a condição de seleção é que o dado DADO exista em um arquivo plano.
Seria equivalente ao uso da condição EXISTS, do Sql. sendo que, no nosso caso, a lista com os critérios de seleção está em um arquivo texto.
Vejamos o código, simples, para tratar a situação.
procedure TForm1.pega_do_txt;
var lista : TStringList;
n,ind : integer;
begin
// carrega Txt para a lista, e a ordena
lista := TStringList.Create();
lista.LoadFromFile('c:\revista_delphi\dado.txt');
lista.Sorted := true;
// o SORTED é necessário para uso do FIND, mais adiante
// lê a tabela A, e verifica se existe o dado na lista - "n" é meramente ilustrativo
n := 6;
tab_A.Active := true;
tab_A.First;
while not tab_A.eof do
begin
if lista.Find(tab_A.Fields[n].Value, ind) then
begin
// trata linha selecionada
end;
tab_A.Next;
end;
tab_A.Active := false;
lista.Free;
end; Comentários:
1. Memória ocupada: Se o arquivo texto tem 10.000 linhas, por exemplo, e o dado buscado tem 20 caracteres de comprimento, a stringlist irá ocupar algo em torno de 0,2MB apenas.
2. A propriedade SORTED foi setada por ser uma condição para o método FIND funcionar.
3. Observe que a posição do DADO na lista ficou anotada no campo ind. Isso será utilizado nos próximos exemplos.
4. Em complemento ao método loadfromfile, que foi utilizado no exemplo, existe o savetofile, que permite que os dados da lista, de uso bem simples, sejam despejados em um arquivo plano.
Caso 2. Indexando.
Suponha agora duas tabelas. Na primeira, tab_A, existe um campo, COD que servirá para buscar um DADO na segunda tabela, tab_B.
Na tab_B, existem dois campos: COD e DADO. Esse dado será recuperado de tab_B sempre que COD for encontrado.
Ou seja: toma-se COD de A e procura-se em B: se encontrado, recupera-se DADO.
O programa fica assim: os dois campos da tabela B, COD e DADO, são carregados em listas na memória; em seguida, para cada linha da tabela A, pesquisa-se COD na lista B, recuperando-se o dado DADO.
(Vamos modificar o exemplo anterior, acrescentando mais uma lista, ficando uma para COD, e outra para DADO. Também, as tabelas serão lidas do banco de dados, e não mais de um arquivo texto.)
Mas, agora surge um problema: se carregarmos as duas listas distintas, e em seguida fizermos a ordenação, perdem-se as relações entre as posições dos itens das duas. Para evitar isso, usaremos duas técnicas diferentes, a seguir:
- alternativa 1: ordenando as duas listas juntas
Uma alternativa é agregar COD + DADO numa só lista, ordenar, e em seguida, desmembrar em duas listas, que manterão a posição relativa entre os itens. O desmembramento é necessário porque, se mantivéssemos os dados agregados, o FIND não iria encontrá-los.
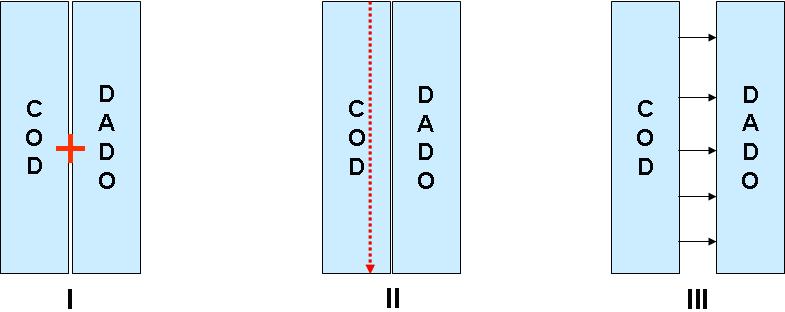 Figura 1 - Ordenação das duas listas como um todo (juntas em uma única lista)
Figura 1 - Ordenação das duas listas como um todo (juntas em uma única lista)
No passo I, são agregados COD e DADO numa só lista; No passo II, COD + DADO é ordenado, e;
No passo III, COD e DADO são segregados ficando, porém nas mesmas posições nas respectivas listas.
O código fica:
procedure TForm1.indexando_ordenando_as_duas;
var lst_COD,lst_DADO : TStringList;
n,ind : integer;
dado_recuperado : string;
begin
lst_COD := TStringList.Create();
lst_DADO := TStringList.Create();
// carrega COD e DADO da tabela B, usando uma query
query.SQL.Text := 'select COD, DADO from tabela_B';
query.Active := true;
query.First;
while not query.eof do
begin
lst_COD.Add(query.Fields[0].value + query.Fields[1].value);
query.Next;
end;
query.Active := false;
lst_COD.Sort; // ordena os pares de dados
lst_COD.Sorted := false;
// agora, desmembra a lista em duas, com os itens emparelhados
for ind := 0 to lst_COD.Count - 1 do
begin
lst_DADO.add(copy(lst_COD[ind], 4, 99));
// no caso, o comprimento de COD seria 3
lst_COD[ind] := copy(lst_COD[ind], 1, 3);
end;
lst_COD.Sorted := true;
// lê a tabela A, e verifica se existe o dado na lista -
//"n" é meramente ilustrativo
n := 6;
tab_A.Active := true;
tab_A.First;
while not tab_A.eof do
begin
if lst_COD.Find(tab_A.Fields[n].Value, ind) then
//dado_recuperado := lst_DADO[ind]
else
dado_recuperado := '';
tab_A.Next;
end;
tab_A.Active := false;
lst_COD.Free;
lst_DADO.Free;
end; Comentário:
No exemplo acima, confiamos que o comprimento de COD fosse fixo. Caso seja necessário trabalhar com formatos que não resultem em strings fixos, como inteiros, por exemplo, sugerimos que a “chave” carregada na lista seja formatada pela função FORMAT. Assim também pode ser feito quando a chave de busca é formada por múltiplos campos.
- alternativa 2: indexação relativa
A segunda alternativa é construir um vetor (uma lista), carregada apenas com os índices relativos, apontando para a outra lista donde os dados serão recuperados.
Isso é útil, por exemplo, quando DADO, do exemplo anterior, é uma estrutura ou registro, com vários campos, ou ponteiros, ou marcadores, etc. Enfim, quando não se for conveniente que DADO participe da ordenação.
Nesse caso, ao carregarmos a lista COD, carregamos a lista DADO ao mesmo tempo, e a posição em que o dado foi inserido (ind) ficará agregada junto a COD. Depois da ordenação, COD e o índice de DADO são desmembrados em duas listas. Agora são três listas.
Esquematicamente, fica assim:
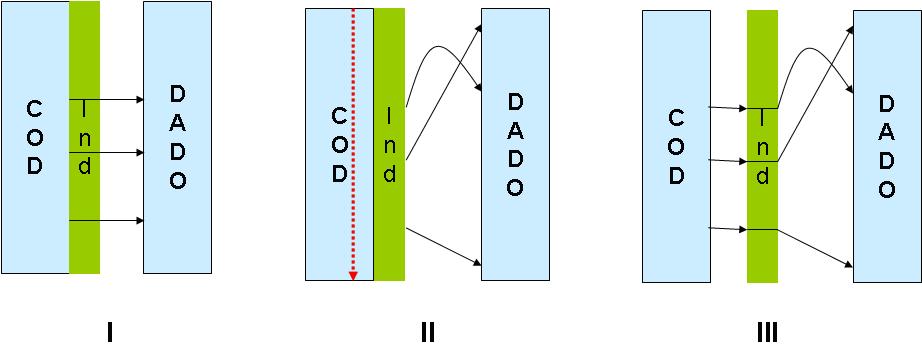 Figura 2 - Utilizando uma lista/vetor auxiliar
Figura 2 - Utilizando uma lista/vetor auxiliar
No passo I, são carregadas as listas, e a posição relativa é anotada junto a COD;
No passo II, COD e seu antigo índice são ordenados, e;
No passo III, COD e o índice são desmembrados, ficando o índice como “ponte” para DADO
Esse exemplo ilustra uma técnica forte, que pode ser útil em várias situações.
procedure TForm1.indexando_relativo;
var lst_COD,
lst_DADO,
lst_IND : TStringList;
n,ind : integer;
dado_recuperado : string;
begin
lst_COD := TStringList.Create();
lst_DADO := TStringList.Create();
lst_IND := TStringList.Create();
// carrega COD e DADO da tabela B, usando uma query
query.SQL.Text := 'select COD, DADO from tabela_B';
query.Active := true;
query.First;
ind := -1;
while not query.eof do
begin
inc(ind);
lst_COD.Add(query.Fields[0].value + inttostr(ind));
lst_DADO.Add(query.Fields[1].value);
query.Next;
end;
query.Active := false;
lst_COD.Sort; // ordena os codigos, mais os índices para dados
lst_COD.Sorted := false;
// agora, desmembra a lista em duas
for ind := 0 to lst_COD.Count - 1 do
begin
lst_IND.add(copy(lst_COD[ind], 4, 99));
// no caso, o comprimento de COD seria 3
lst_COD[ind] := copy(lst_COD[ind], 1, 3);
end;
lst_COD.Sorted := true;
// lê a tabela A, e verifica se existe o dado na lista
//"n" é meramente ilustrativo
n := 6;
tab_A.Active := true;
tab_A.First;
while not tab_A.eof do
begin
if lst_COD.Find(tab_A.Fields[n].Value, ind) then
dado_recuperado := lst_DADO[ strtoint(lst_IND[ ind ]) ]
else
dado_recuperado := '';
tab_A.Next;
end;
tab_A.Active := false;
lst_COD.Free;
lst_DADO.Free;
lst_IND.Free;
end;
Caso 3. Uma aplicação.
Imaginemos agora duas tabelas, uma de ORÇAMENTOS, e outra de VENDAS realizadas, e desejamos saber o percentual de rejeição dos orçamentos, por produto.
Na tabela VENDAS está registrado o número do orçamento que deu origem à venda, mais o código do produto.
Porém, na tabela ORÇAMENTOS, não há referência se o orçamento foi aceito ou rejeitado. Essa tabela contém apenas o número do orçamento e o código do produto,
Ambas as tabelas têm em torno de 1.500.000 linhas. O número do orçamento é um código numérico, de 8 posições. Sabemos também que a tabela de PRODUTOS tem em torno de 5.000 linhas.
Então, se carregarmos todos os números de orçamentos, que estão na tabela VENDAS, para uma lista, tal lista ocupará em torno de 12MB, o que é bastante viável.
Trabalharemos então com a seguinte estrutura:
- duas listas, a primeira com os códigos de todos os produtos, ordenados, e, a segunda, com os códigos dos orçamentos aceitos, ou seja, que se transformaram em vendas.
- e mais um vetor de duas posições inteiras, com uma entrada para cada produto, onde serão armazenados contadores dos orçamentos emitidos, e dos orçamentos aceitos.
A indexação do vetor será relativa à lista de produtos.
Esquematicamente, fica assim:
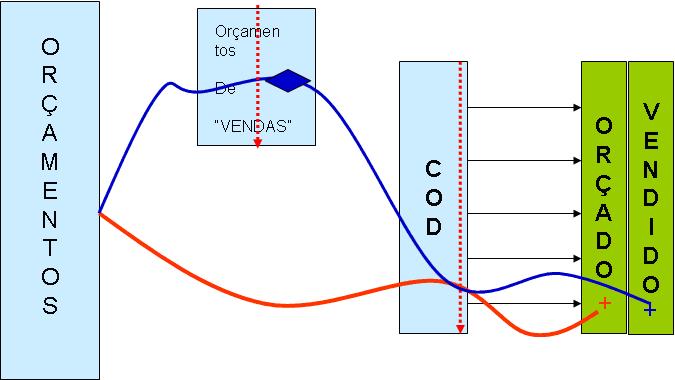 Figura 3 - Aplicação das ordenações
Figura 3 - Aplicação das ordenações
O programa, então, fica:
- carregam-se todos os códigos de orçamentos que estão na tabela VENDAS para uma lista, que também é ordenada. (Orçamentos de “Vendas”)
- carregam-se os códigos dos produtos para outra lista, que é depois ordenada. (COD)
- tomam-se todos os orçamentos (código do orçamento e código do produto), da tabela ORÇAMENTOS, e:
soma-se 1 ao contador ORÇADO do produto, e:
se o orçamento existe na tabela de VENDAS (ou seja, na lista que foi carregada), soma-se 1 ao contador VENDIDO do produto.
Vamos ao código:
procedure TForm1.contando_os_orcamentos;
var lst_PROD,
lst_ORCS : TStringList;
conta : array[1..10000,1..2] of integer; // 1-orcado; 2-vendido
ind,aux : integer;
orcado, vendido : integer;
begin
orcado := 1;
vendido:= 2;
lst_PROD := TStringList.Create();
lst_ORCS := TStringList.Create();
// carrega os códigos dos produtos, usando uma query
query.SQL.Text := 'select PROD from PRODUTOS';
query.Active := true;
query.First;
ind := 0;
while not query.eof do
begin
lst_PROD.Add(query.Fields[0].Value);
inc(ind);
conta[ind,orcado] := 0;
conta[ind,vendido] := 0;
query.Next;
end;
query.Active := false;
// carrega os códigos dos orçamentos que vingaram
query.SQL.Text := 'select COD_ORC from VENDAS';
query.Active := true;
query.First;
ind := -1;
while not query.eof do
begin
lst_ORCS.Add(query.Fields[0].value);
query.Next;
end;
query.Active := false;
lst_PROD.Sorted := true;
lst_ORCS.Sorted := true;
// carrega os orçamentos, e verifica se foram aceitos ou não
query.SQL.Text := 'select COD_ORC,PROD from ORCAMENTOS';
query.Active := true;
query.First;
while not query.eof do
begin
lst_PROD.Find(query.Fields[1].value,ind); //pega o índice do produto
inc(conta[ind, orcado]); //conta orçamento
if lst_ORCS.Find(query.Fields[0].value, aux) then // conta se foi aceito
inc(conta[ind, vendido]);
query.Next;
end;
query.Active := false;
lst_PROD.Free;
lst_ORCS.Free;
end; Comentário:
A lista de produtos poderia ser já uma lista de um componente STRINGBAND, por exemplo.
Esse caso poderia ser modificado para incluir as tuplas (COD, Descrição e contadores, etc) descritas em registros, e o vetor passar a ser uma estrutura com tais registros.
Conclusão.
Utilizando principalmente uma classe e dois métodos da classe, demonstramos como é simples tratar dados, de modo consciente e eficiente, em memória. Ou seja, pode ser simples implementarmos estratégias personalizadas para o tratamento dos dados, o que quase sempre representa um ganho significativo de desempenho para a aplicação.
Então, se juntarmos o conhecimento formal de estruturas de dados, com os poderosos recursos que o Delphi disponibiliza, poderemos primar pela eficiência da programação, sem comprometer os prazos de desenvolvimento. E mais, podemos avançar no tratamento de estruturas complexas, como grafos, por exemplo, lançando mão apenas da nossa ferramenta básica do dia-a-dia.
Por: Pedro Jales - Graduado em Engenharia Química, e pós-graduado em Engenharia de Sistemas e em Administração de Empresas. Começou a programar em 1975, inicialmente em Fortran e Cobol. Trabalhou como Analista de Sistemas de 1978 a 2002, desenvolvendo programação, Projetos de Sistemas e Análise Organizacional. Programa em Delphi desde 1998. Contato: pedrojales@ig.com.br
Dica do Editor
Listas em memória podem ajudam a obter melhor performance em vários casos, porém, os exemplos de pesquisa e ordenação mostrados nesta artigo do amigo Pedro Jales não devem ser considerados como a melhor forma para lidar com banco de dados, seja um SGBD ou um com dados somente em memória.
Nestes casos é melhor utilizar um componente já pronto, como um ClientDataSet, um RxMemoryData ou um JvMemoryData para realizar as operações de ordenação (por índice virtual em memória), filtro (propriedade Filter), busca (Locate, FindKey, FindNearest), etc, para não ter que reinventar a roda e desfrutar de códigos já testados e aprovados por tantas pessoas.
Utilizar listas em memória são úteis em cruzamento de dados, em aplicações críticas ou com certa limitação de hardware.
Além disso, há outros tipos de listas (que não a StringList) que podem ser utilizadas em processamentos críticos. Um exemplo disto é trabalhar com ponteiros e montar os apontamentos entre os endereços diretamente no registro armazenado neles.
Veja abaixo alguns materiais aqui do site, sobre listas e dados em memória que podem ser úteis:
Usando Record, Ponteiro e TList Criando tabelas temporárias Criando arquivos XML com ClientDataSet com Pesquisa e Ordenação de Colunas
Nenhum comentário:
Postar um comentário